

{kind=link}
Last Updated on septiembre 30, 2024 12:15 pm by Laszlo Szabo / NowadAIs | Published on septiembre 30, 2024 by Laszlo Szabo / NowadAIs
Meta’s Llama 3.2: El rebaño de la IA entra en territorio multimodal – Notas clave:
- Meta presenta Llama 3.2, una colección de modelos de IA multimodal que procesan tanto texto como imágenes
- Los modelos van de 1B a 90B parámetros, aptos para su despliegue en el dispositivo o en la nube
- El lanzamiento de código abierto pretende democratizar la tecnología de IA en diversas plataformas
Un salto pionero hacia la multimodalidad
Meta ha presentado Llama 3.2, una innovadora colección de modelos de lenguaje multimodales (LLM) capaces de procesar tanto texto como imágenes. Este lanzamiento pionero marca la incursión de Meta en el reino de la IA multimodal, dando paso a una nueva era de aplicaciones versátiles e inteligentes capaces de comprender y razonar a través de diversas modalidades de datos.
Llama 3.2 representa la búsqueda de Meta de tecnologías de IA abiertas y accesibles. Basándose en el éxito de su predecesora, Llama 3.1, que causó sensación con su enorme modelo de 405.000 millones de parámetros, Llama 3.2 introduce una serie de modelos más pequeños y eficientes adaptados para su despliegue en dispositivos móviles y periféricos.
Reducción para aumentar la escalabilidad
Mientras que el gran tamaño y las exigencias computacionales del modelo Llama 3.1 limitaban su accesibilidad, Llama 3.2 pretende democratizar la IA ofreciendo modelos que puedan ejecutarse en entornos con recursos limitados. Este movimiento estratégico reconoce la creciente demanda de capacidades de IA en los dispositivos, permitiendo a los desarrolladores crear aplicaciones personalizadas que preserven la privacidad y aprovechen la potencia de la IA generativa sin depender de los recursos informáticos de la nube.
El rebaño Llama 3.2: Diversidad de capacidades
“Llama 3.2 es una colección de grandes modelos lingüísticos (LLM) preentrenados y afinados en tamaños 1B y 3B que son sólo texto multilingüe, y tamaños 11B y 90B que toman tanto texto como imágenes de entrada y texto de salida”
Meta declaró.
Llama 3.2 incluye una amplia gama de modelos, cada uno de ellos adaptado a casos de uso y escenarios de implantación específicos:
Modelos ligeros de sólo texto (1B y 3B)
Los modelos ligeros 1B y 3B están diseñados para un despliegue eficiente en el dispositivo y admiten la generación de texto multilingüe y funciones de llamada a herramientas. Estos modelos permiten a los desarrolladores crear aplicaciones con gran capacidad de respuesta y respetuosas con la privacidad que pueden resumir mensajes, extraer elementos de acción y aprovechar herramientas locales como calendarios y recordatorios sin depender de servicios en la nube.
Modelos de visión multimodal (11B y 90B)
Los modelos de mayor tamaño 11B y 90B incorporan funciones multimodales revolucionarias que les permiten procesar tanto texto como imágenes. Estos modelos destacan en tareas como la comprensión a nivel de documento, incluida la interpretación de tablas y gráficos, el subtitulado de imágenes y la localización visual de objetos a partir de descripciones en lenguaje natural.
Aumento del rendimiento y la eficacia
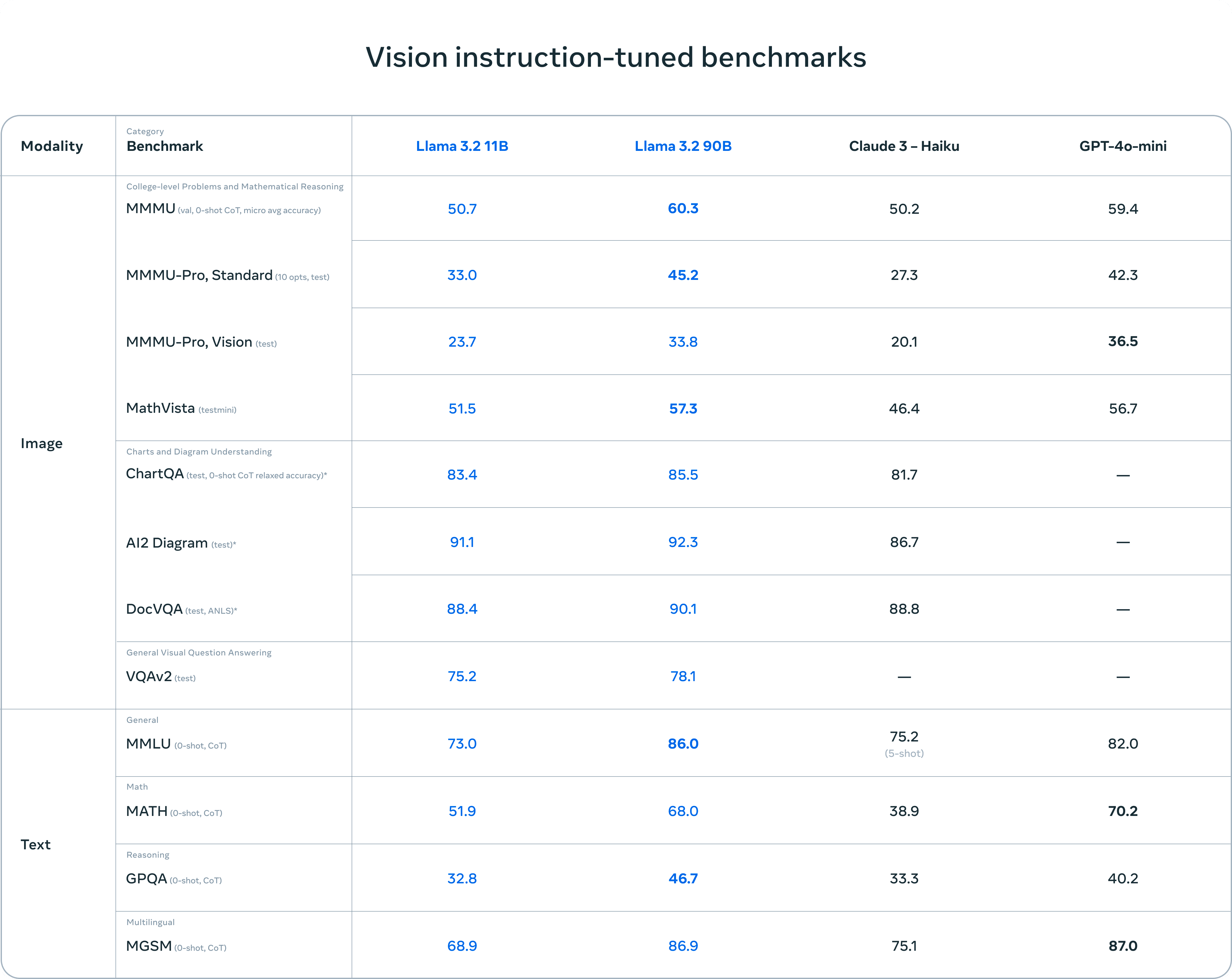
Meta ha empleado una serie de técnicas avanzadas para optimizar el rendimiento y la eficiencia de los modelos Llama 3.2. Se han utilizado métodos de poda y destilación para crear modelos más pequeños que conserven los conocimientos y capacidades de sus homólogos más grandes, mientras que la destilación de conocimientos se ha empleado para mejorar el rendimiento de los modelos ligeros.
Las exhaustivas evaluaciones llevadas a cabo por Meta sugieren que los modelos Llama 3.2 son competitivos frente a los modelos básicos líderes del sector, como Claude 3 Haiku y GPT4o-mini, en una amplia gama de pruebas comparativas que abarcan la comprensión de imágenes, el razonamiento visual y las tareas lingüísticas.
Liberar el potencial multimodal
La introducción de funciones multimodales en Llama 3.2 abre un mundo de posibilidades tanto para desarrolladores como para investigadores. Imagine aplicaciones capaces de comprender y razonar sobre datos visuales complejos, como informes financieros, diagramas o planos arquitectónicos, proporcionando información y respondiendo a preguntas basadas tanto en datos textuales como visuales.
Las aplicaciones de realidad aumentada (RA) podrían aprovechar la destreza multimodal de Llama 3.2 para ofrecer una comprensión en tiempo real del entorno del usuario, permitiendo una integración perfecta de la información digital con el mundo físico. Los motores de búsqueda visual podrían mejorarse para ordenar y categorizar las imágenes en función de su contenido, revolucionando la forma en que interactuamos con los datos visuales y los exploramos.
Innovación responsable: Salvaguardar el impacto de la IA
Como con cualquier tecnología potente, Meta reconoce la importancia de la innovación responsable y ha puesto en marcha una estrategia integral para gestionar los riesgos de confianza y seguridad asociados a Llama 3.2. Este triple enfoque tiene como objetivo permitir a los desarrolladores desplegar experiencias útiles, seguras y flexibles, proteger contra los usuarios adversarios que intenten explotar las capacidades de los modelos, y proporcionar protecciones para la comunidad en general.
Llama 3.2 se ha sometido a un exhaustivo ajuste de seguridad, empleando un enfoque multifacético para la recopilación de datos, incluyendo datos generados por humanos y datos sintéticos, para mitigar los riesgos potenciales. Además, Meta ha introducido Llama Guard 3, una salvaguarda específica diseñada para apoyar las capacidades de comprensión de imágenes de Llama 3.2 filtrando los mensajes de entrada de imágenes de texto y las respuestas de salida.
Democratizar la IA a través del código abierto
En línea con el compromiso de Meta con la apertura y la accesibilidad, los modelos de Llama 3.2 están disponibles para su descarga en el sitio web de Llama y en el popular repositorio Hugging Face. Además, Meta ha colaborado con un amplio ecosistema de socios, incluidos AMD, AWS, Databricks, Dell, Google Cloud, Groq, IBM, Intel, Microsoft Azure, NVIDIA, Oracle Cloud y Snowflake, para permitir la integración y el despliegue sin problemas de Llama 3.2 en diversas plataformas y entornos.
Pila Llama: Agilizando el desarrollo de IA
Reconociendo las complejidades que conlleva la creación de aplicaciones agenticas con grandes modelos de lenguaje, Meta ha introducido Llama Stack, una completa cadena de herramientas que agiliza el proceso de desarrollo. Llama Stack proporciona una interfaz estandarizada para componentes canónicos, como el ajuste fino, la generación de datos sintéticos y la integración de herramientas, lo que permite a los desarrolladores personalizar los modelos Llama y construir aplicaciones agénticas con funciones de seguridad integradas.
Las distribuciones de Llama Stack están disponibles para varios escenarios de despliegue, incluidos los entornos de nodo único, en las instalaciones, en la nube y en el dispositivo, lo que permite a los desarrolladores elegir la estrategia de despliegue más adecuada para sus aplicaciones.
Acelerar la innovación mediante la colaboración
El compromiso de Meta con el código abierto y la colaboración ha fomentado un próspero ecosistema de socios y desarrolladores. La empresa ha colaborado estrechamente con líderes del sector como Accenture, Arm, AWS, Cloudflare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM watsonx, Infosys, Intel, Kaggle, Lenovo, LMSYS, MediaTek, Microsoft Azure, NVIDIA, OctoAI, Ollama, Oracle Cloud, PwC, Qualcomm, Sarvam AI, Scale AI, Snowflake, Together AI y el proyecto vLLM de UC Berkeley.
Este enfoque colaborativo no sólo ha facilitado el desarrollo de Llama 3.2, sino que también ha fomentado un vibrante ecosistema de aplicaciones y casos de uso, mostrando el poder de la innovación abierta y el potencial de la IA para impulsar un cambio positivo en diversos dominios.
Descripciones
- Grandes modelos lingüísticos (LLM): Sistemas avanzados de IA entrenados en grandes cantidades de datos de texto para comprender y generar un lenguaje similar al humano.
- Inteligencia artificial multimodal: sistemas capaces de procesar y comprender simultáneamente varios tipos de datos, como texto e imágenes.
- Edge computing: Procesamiento de datos cerca de la fuente de información, a menudo en dispositivos móviles o servidores locales, en lugar de en la nube.
- Ajuste: Proceso de adaptación de un modelo de IA previamente entrenado para realizar tareas específicas o trabajar con datos especializados.
- Destilación de conocimientos: Técnica para transferir conocimientos de un modelo más grande y complejo a otro más pequeño y eficiente.
Preguntas más frecuentes
- ¿En qué se diferencia Meta’s Llama 3.2 de las versiones anteriores? Meta’s Llama 3.2 introduce capacidades multimodales, lo que le permite procesar tanto texto como imágenes. También ofrece una gama de tamaños de modelo, desde versiones ligeras de 1B parámetro hasta potentes modelos de 90B parámetros.
- ¿Se puede utilizar Meta’s Llama 3.2 en dispositivos móviles? Sí, Meta’s Llama 3.2 incluye modelos más pequeños (parámetros 1B y 3B) diseñados específicamente para un despliegue eficiente en dispositivos, incluidos los móviles.
- ¿Cómo se compara Llama 3.2 de Meta con otros modelos de IA en términos de rendimiento? De acuerdo con las evaluaciones de Meta, los modelos Llama 3.2 son competitivos con los modelos base líderes de la industria, como Claude 3 Haiku y GPT4o-mini, en varios benchmarks.
- ¿Está disponible Llama 3.2 de Meta para uso de los desarrolladores? Sí, Meta ha puesto a disposición de los desarrolladores los modelos Llama 3.2 para su descarga en el sitio web de Llama y en el repositorio Hugging Face, lo que permite a los desarrolladores acceder a la tecnología e implementarla.
- ¿Qué medidas de seguridad ha implementado Meta en Llama 3.2? Meta ha llevado a cabo un exhaustivo ajuste de seguridad para Llama 3.2, utilizando tanto datos generados por humanos como datos sintéticos. También han introducido Llama Guard 3, un sistema de salvaguarda diseñado para filtrar las entradas y salidas de texto e imágenes.